Practical benchmarks showing faster inter-token latency when deploying Qwen3 models with vLLM, Kubernetes, and AWS AI Chips.
Speculative decoding on AWS Trainium can accelerate token generation by up to 3x for decode-heavy workloads, helping reduce the cost per output token and improving throughput without sacrificing output quality. If you build AI writing assistants, coding agents, or other generative AI applications, your workloads likely produce far more tokens than they consume, making the decode stage the dominant cost of inference. During autoregressive decoding, tokens are generated sequentially, leaving hardware accelerators memory-bandwidth-bound and underutilized. This drives up the cost per generated token. Speculative decoding addresses this bottleneck by letting a small draft model propose multiple tokens at once, which the target model verifies in a single forward pass. Fewer serial decode steps means lower latency and higher hardware utilization, helping to reduce your inference costs.
In this post, you will learn:
- How speculative decoding works and why it helps reduce cost per generated token on AWS Trainium2
- How to enable speculative decoding with vLLM on Trainium
- The benchmarking methodology we used to evaluate performance
- How to tune draft model selection and the speculative token window size for your workloads
- Step-by-step instructions to reproduce the results using Qwen3
What is speculative decoding?
Speculative decoding speeds up autoregressive generation by using two models:
- A draft model proposes n candidate tokens quickly.
- A target model verifies them in one forward pass.
For a deeper look at the underlying mechanics, including token acceptance and rejection, EAGLE-based speculation, and general speculative decoding concepts, see blog post
Inferentia2
this SageMaker EAGLE walkthrough
on AWS Inferentia2, this SageMaker EAGLE walkthrough, and
this primer
. Here, we focus on the two knobs you control in practice: the draft model and
num_speculative_tokens
.
The draft and target models must share the same tokenizer and vocabulary, because speculative decoding operates on token IDs verified directly by the target model. We recommend choosing models from the same architectural family because their next-token predictions agree more often. You can pair models with different architectures if they share a tokenizer, but lower agreement between the draft and target models reduces acceptance rates and removes most of the performance gain.
When the target model accepts the draft tokens, they are committed without incurring the full cost of sequential decode steps. The primary parameter you control is
num_speculative_tokens
, which sets how many tokens the draft model proposes at once. Increasing this value lets you skip more serial decode steps per verification pass, directly reducing inter-token latency when acceptance rates are high.
The performance gain comes from two effects. First, speculative decoding reduces the number of target-model decode steps, which lowers the number of KV-cache memory round trips. (The KV cache stores previously computed key and value tensors so the model does not recompute attention for past tokens. Each decode step reads the full cache from memory, making decode memory-bandwidth-bound.) Second, speculative decoding improves hardware utilization during decoding. In standard autoregressive decoding, each decode step produces only a single new token: the accelerator launches expensive matrix-multiply kernels to produce just one token of work, leaving the processing-element engine largely underutilized. During verification, the target model instead processes n tokens at once, amortizing memory access and turning a sequence of small, inefficient single-token computations into a more compute-dense workload. Setting
num_speculative_tokens
too low limits speed gains.
Setting it too high increases the likelihood of early rejections, wasting draft compute and raising target-model verification cost. You tune this value by balancing draft compute against verification cost based on your observed acceptance rate.
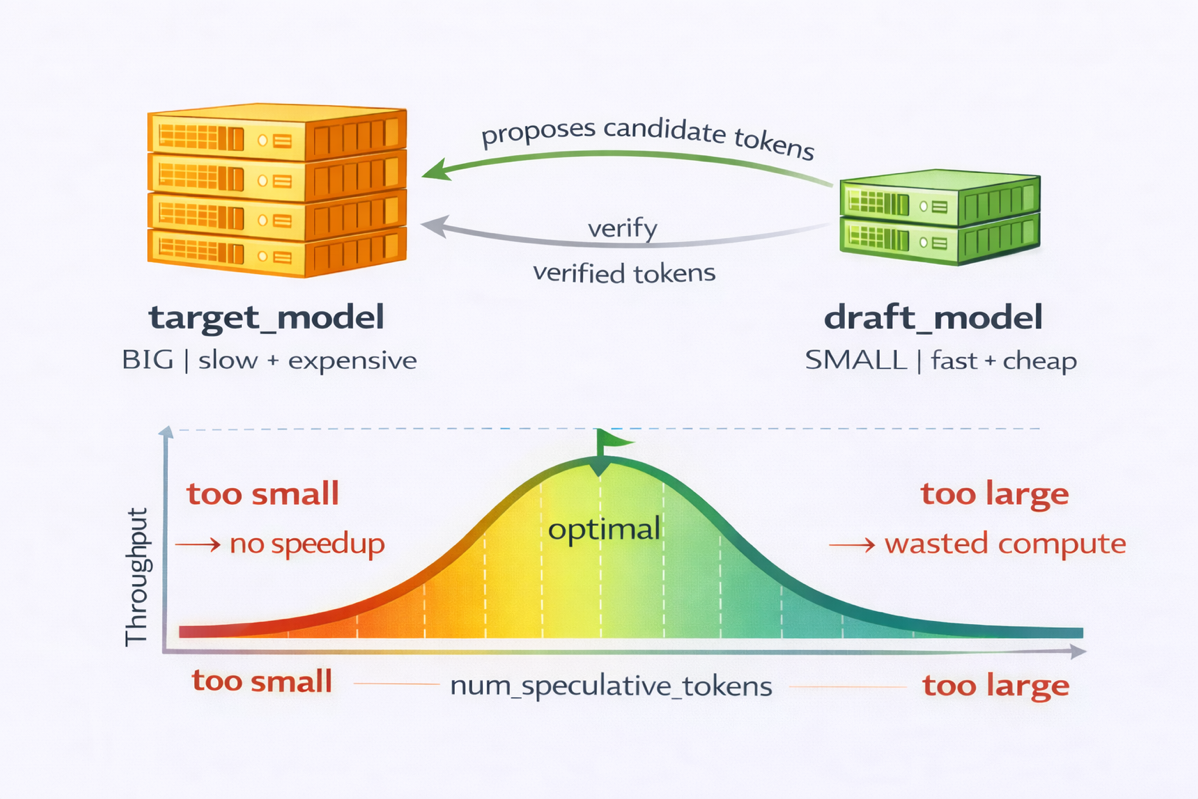
Figure 1 Speculative decoding config tradeoffs
To illustrate these tradeoffs, we compared Qwen3-0.6B and Qwen3-1.7B draft models. The smaller 0.6B model was faster to run, but its acceptance rate was roughly 60% lower, enough to cancel out the compute savings. Qwen3-1.7B struck a better balance between speed and acceptance.
For
num_speculative_tokens
, we evaluated values from 5 to 15. Smaller settings (for example, 5) offered limited speedup. Larger windows (for example, 15) increased rejections and degraded performance. The best configuration depended heavily on prompt structure. We tested both structured prompts (such as repetition, numeric sequences, and simple code) and open-ended natural language. The best balance came from Qwen3-1.7B with 7 speculative tokens. See the Lessons learned section for full tuning details.
What NeuronX Distributed Inference (NxD Inference) supports
AWS Neuron is the SDK for AWS AI chips. NeuronX Distributed Inference (NxDI) is its library for scalable, high-performance LLM inference on Trainium and Inferentia. NxDI provides native support for speculative decoding on Trainium across four modes:
- Vanilla speculative decoding — Separate draft and target models compiled independently. The simplest way to get started.
- Fused speculation — Draft and target models compiled together for improved performance. This is the mode we use in this post.
- EAGLE speculation — The draft model leverages hidden-state context from the target model to improve acceptance rates.
- Medusa speculation — Multiple small prediction heads run in parallel to propose tokens, reducing draft-model overhead.
For complete documentation, see the
Speculative Decoding guide
and the
EAGLE Speculative Decoding guide
. This post uses fused speculation, where the draft model (Qwen3-1.7B) and target model (Qwen3-32B) are compiled together with
enable_fused_speculation=true
for optimal performance on Neuron.
Getting started with speculative decoding on AWS Trainium
We deploy two vLLM inference services on Trainium instances in the same
Amazon Elastic Kubernetes Service (Amazon EKS)
cluster, keeping everything identical except the decoding method to isolate the performance impact. The baseline service (qwen-vllm) serves Qwen3-32B with standard decoding. The speculative service (qwen-sd-vllm) serves the same Qwen3-32B target model, adding a Qwen3-1.7B draft model with
num_speculative_tokens=7
.
Both services run identical configurations on Trn2 (trn2.48xlarge), the same accelerator allocation, tensor parallelism (which distributes model weights across multiple NeuronCores to fit large models), sequence length, batching limits, and Neuron DLC image. The only difference is the addition of the Qwen3-1.7B draft model and
num_speculative_tokens=7
for the speculative service. See Figure 2 for full setup details.
To compare the two configurations under identical load, we used
llmperf
to generate the same traffic patterns against both endpoints. We captured infrastructure telemetry with
CloudWatch Container Insights
and published request-level custom metrics (TTFT, inter-token latency, and end-to-end latency) to CloudWatch dashboards for side-by-side analysis.
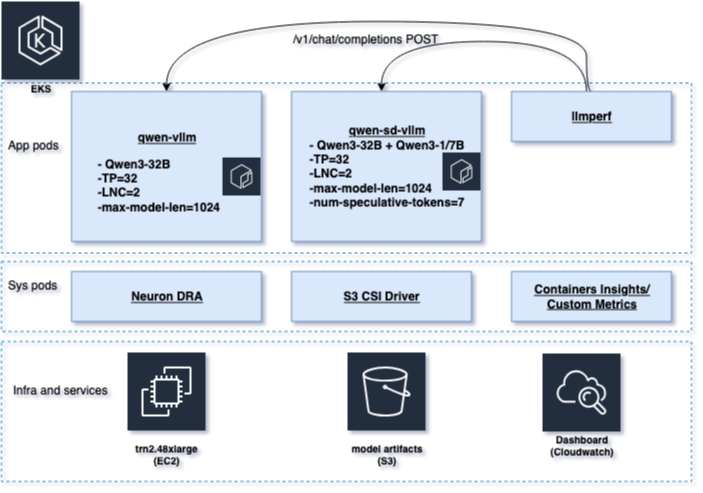
Figure 2 System architecture
Benchmarking setup
We used LLMPerf to run structured, decode-heavy test cases against both the baseline and speculative decoding deployments. The benchmarks ran inside a Kubernetes pod, qwen-llmperf-pod.yaml , issuing concurrent requests to both endpoints and logging token-level latency metrics. Our test cases ranged from highly structured prompts (repetitive sequences, numeric continuations, simple code patterns) to open-ended natural language completions, covering both best-case and worst-case behavior for speculative decoding. The full prompt set is available in the samples repository .
For clarity, we focus the analysis on two representative prompt types: a highly structured, deterministic prompt (repetitive text generation) and an open-ended prompt. These two cases illustrate both the best-case and worst-case behavior of speculative decoding.
The pod ran
llmperf
with controlled input and output lengths and temperature=0.0 to stress deterministic decoding paths. We logged and published metrics including inter-token latency, TTFT, throughput, and end-to-end latency to
CloudWatch
.
Results
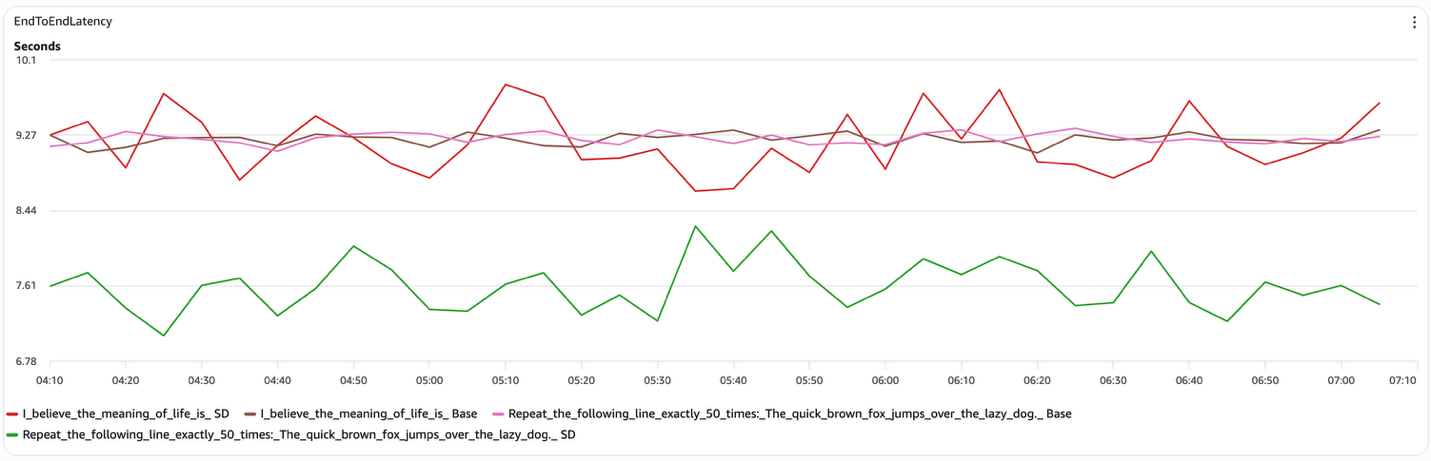
Figure 3 Speculative decoding E2E latency
Speculative decoding reduces latency selectively: its effectiveness depends strongly on prompt structure, and this dependency appears consistently across the measured metrics. Here is what you can expect for each prompt type:
- Structured prompts (for example, “Repeat the following line exactly 50 times”). Speculative decoding delivers a measurable reduction in end-to-end latency. When the draft model reliably predicts what the target model would generate, the system skips a substantial fraction of target-model decode steps. In our tests, inter-token latency dropped to roughly 15 ms per token (compared to approximately 45 ms for open-ended prompts), and the speculative decoding curve remained consistently below the baseline throughout the run.
- Open-ended prompts (for example, “I believe the meaning of life is”). Speculative decoding provides no consistent benefit. The draft model frequently diverges from the target model, causing token rejections that negate the potential gains. The speculative and baseline end-to-end latency curves largely overlap, and inter-token latency stays near 45 ms per token for both configurations.
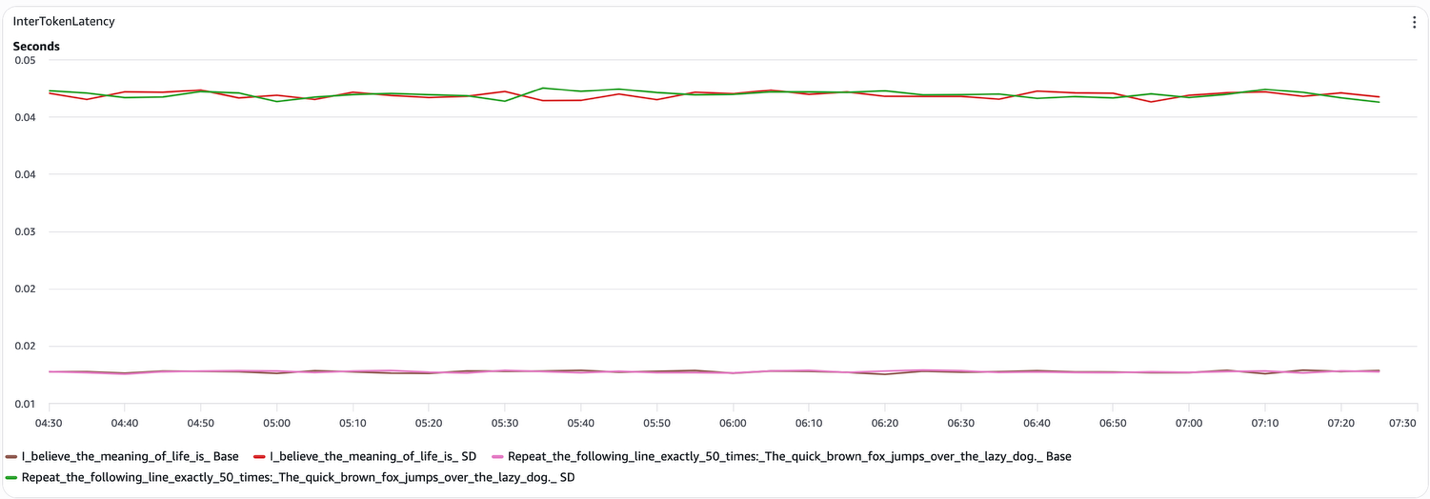
Figure 4 Speculative decoding inter-token latency (Decode)
TTFT (Time to First Token) remains effectively unchanged across the configurations (Figure 5). TTFT is dominated by the prefill phase, where the model encodes the input context. Speculative decoding does not alter this stage, so prefill latency is neither improved nor degraded.
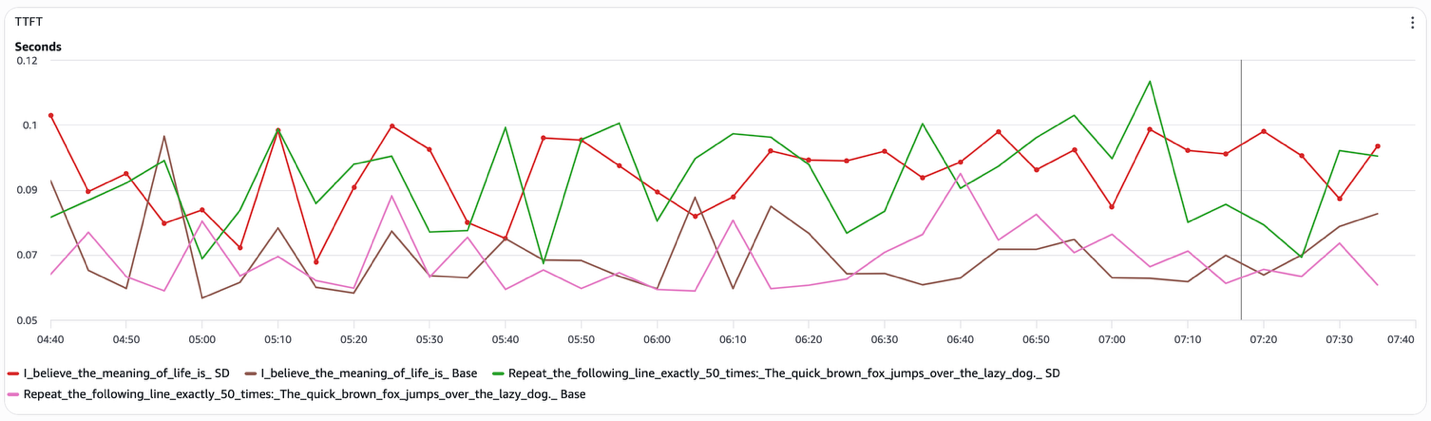
Figure 5 Speculative decoding TTFT (Prefill)
Taken together, these results show that speculative decoding improves total latency by reducing the number of target-model decode steps executed, not by accelerating the decode step itself or the prefill stage. This explains why gains appear in end-to-end latency for structured prompts, but are absent in inter-token latency and TTFT, and why speculative decoding returns to baseline behavior for open-ended generation.
Reproducing the results
We provide end-to-end code samples and Kubernetes configurations in the AWS Neuron EKS samples repository . The repository includes:
- Kubernetes manifests for deploying baseline vLLM and speculative decoding vLLM services on Trn2
- Example vLLM configuration flags for enabling fused speculative decoding
- Sample
llmperfbenchmarking scripts used to generate load and collect metrics - Instructions for mounting model checkpoints and compiled artifacts through the S3 CSI Driver
- Guidance on configuring Neuron DRA, tensor parallelism, and NeuronCore placement
These samples let you recreate the same experimental setup used in this post, from model deployment through benchmarking and metrics collection.
Conclusion
Decode-heavy LLM workloads are constrained by the sequential nature of autoregressive generation. Speculative decoding breaks this bottleneck on AWS Trainium2 by reducing the number of target-model decode steps needed to produce the full output, effectively increasing the tokens generated per forward pass. For workloads where the output space is predictable, such as code generation, structured data extraction, templated report generation, or configuration file synthesis, this can translate directly to lower cost per output token and higher throughput, without sacrificing quality. Speculative decoding is not a universal optimization. Its effectiveness depends on prompt structure, draft-model quality, and speculative parameter tuning. When applied to the right workloads, it delivers meaningful latency and cost improvements on Trainium-based inference systems.
Next steps
To get started with speculative decoding on AWS Trainium, explore these resources:
About the authors
Yahav Biran is a Principal Architect at Amazon, focusing on large-scale AI workloads. He contributes to open-source projects and publishes in AWS blogs and academic journals, including the AWS compute and AI blogs and the Journal of Systems Engineering. He frequently delivers technical presentations and collaborates with customers to design Cloud applications. Yahav holds a Ph.D. in Systems Engineering from Colorado State University.
Truong Pham is a software engineer at Annapurna Labs, Amazon. He specializes in optimizing large language model inference performance on AWS AI accelerators such as AWS Inferentia and Trainium — and designing developer-friendly APIs for the AWS Neuron software stack. Truong holds a Ph.D. in Chemical Engineering from the University of Minnesota.